Racial Bias
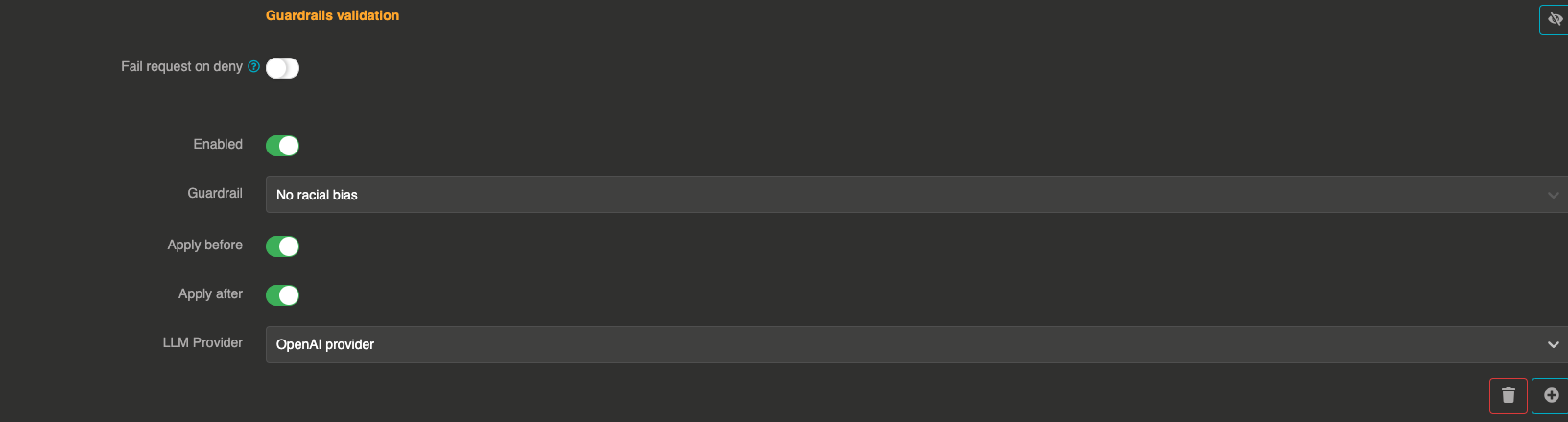
The Racial bias guardrail detects and blocks messages containing racial bias. It uses a dedicated LLM provider with a hardcoded prompt to identify stereotyping, discriminatory language, microaggressions, and other forms of racial prejudice.
It can be applied before sending the prompt to the LLM (blocking biased prompts) and after to filter biased responses.
How it works
The guardrail sends messages to a validation LLM with a specialized system prompt that instructs it to detect:
- Stereotyping — Associating specific roles, behaviors, or characteristics with a particular racial or ethnic group
- Discriminatory language — Offensive terms, slurs, or language that demeans or marginalizes a racial group
- Microaggressions — Subtle comments that reinforce stereotypes or racial hierarchy
- Unequal treatment — Suggesting that one racial group is superior/inferior
- Cultural appropriation — Using elements of a marginalized culture without respect
- Racialized expectations — Imposing expectations based on race
Configuration
"guardrails": [
{
"enabled": true,
"before": true,
"after": true,
"id": "racial_bias",
"config": {
"provider": "provider_xxxxxxxxx"
}
}
]
Field explanations
- enabled:
true— The guardrail is active - before:
true— The guardrail applies to user input before sending to the LLM - after:
true— The guardrail applies to the LLM response
Config section
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
provider | string | Yes | — | Reference ID of the LLM provider used to evaluate messages for racial bias. Must be different from the main provider. |
err_msg | string | No | "This message has been blocked by the 'racial-bias' guardrail !" | Custom error message returned when a message is blocked. |
Guardrail example
If a user asks, "As an Asian, you must be good at math, right?", the LLM will detect racialized expectations and block the request.
If the LLM generates a response that contains racial stereotypes, it will be blocked before reaching the user.