Prompt contains gibberish guardrail
This guardrail acts like a filter that detects and manages inputs that are nonsensical, random, or meaningless, preventing the AI from generating irrelevant or low-quality responses. It uses a dedicated LLM provider with a hardcoded prompt to detect gibberish content.
This can be applied before the LLM processes the input (blocking nonsense prompts) and after to filter out meaningless responses.
How it works
The guardrail sends messages to a validation LLM with a system prompt that instructs it to determine whether the content is gibberish. The validation LLM responds with true (content is meaningful) or false (content is gibberish).
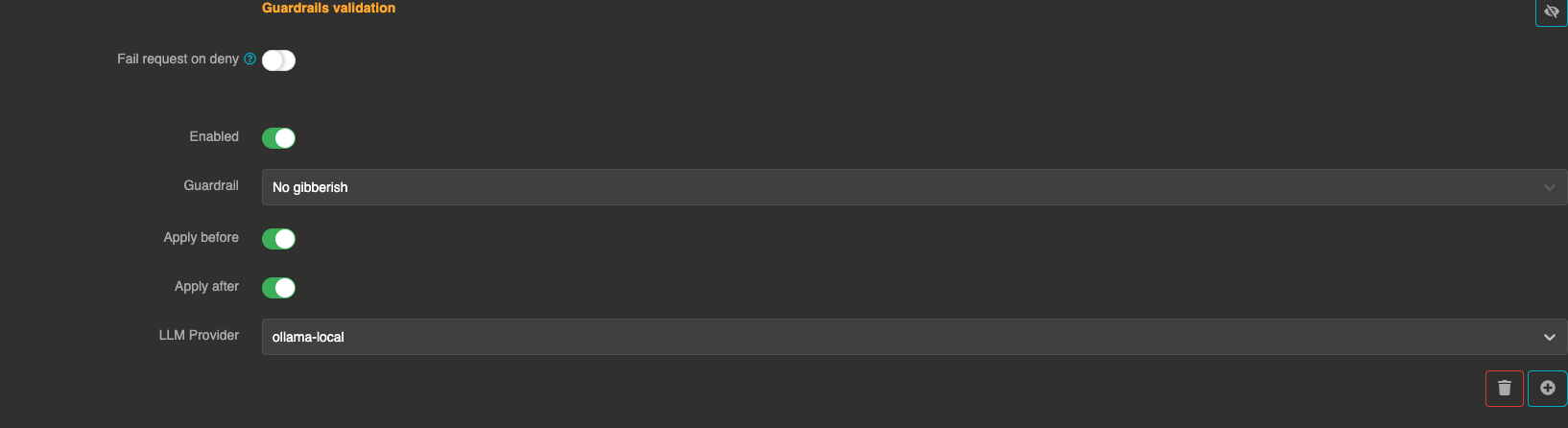
Configuration
"guardrails": [
{
"enabled": true,
"before": true,
"after": true,
"id": "gibberish",
"config": {
"provider": "provider_xxxxxxxxx"
}
}
]
Field explanations
- enabled:
true— The guardrail is active - before:
true— The guardrail applies to user input before sending to the LLM - after:
true— The guardrail applies to the LLM response
Config section
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
provider | string | Yes | — | Reference ID of the LLM provider used to evaluate messages for gibberish. Must be different from the main provider. |
err_msg | string | No | "This message has been blocked by the 'gibberish' guardrail !" | Custom error message returned when a message is blocked. |
Guardrail example
If a user inputs, "asdkjfhasd lkj3r2lkkj!!", the LLM will recognize it as gibberish and block the request.
If the LLM generates a nonsensical response, it will be flagged and removed.