Language moderation
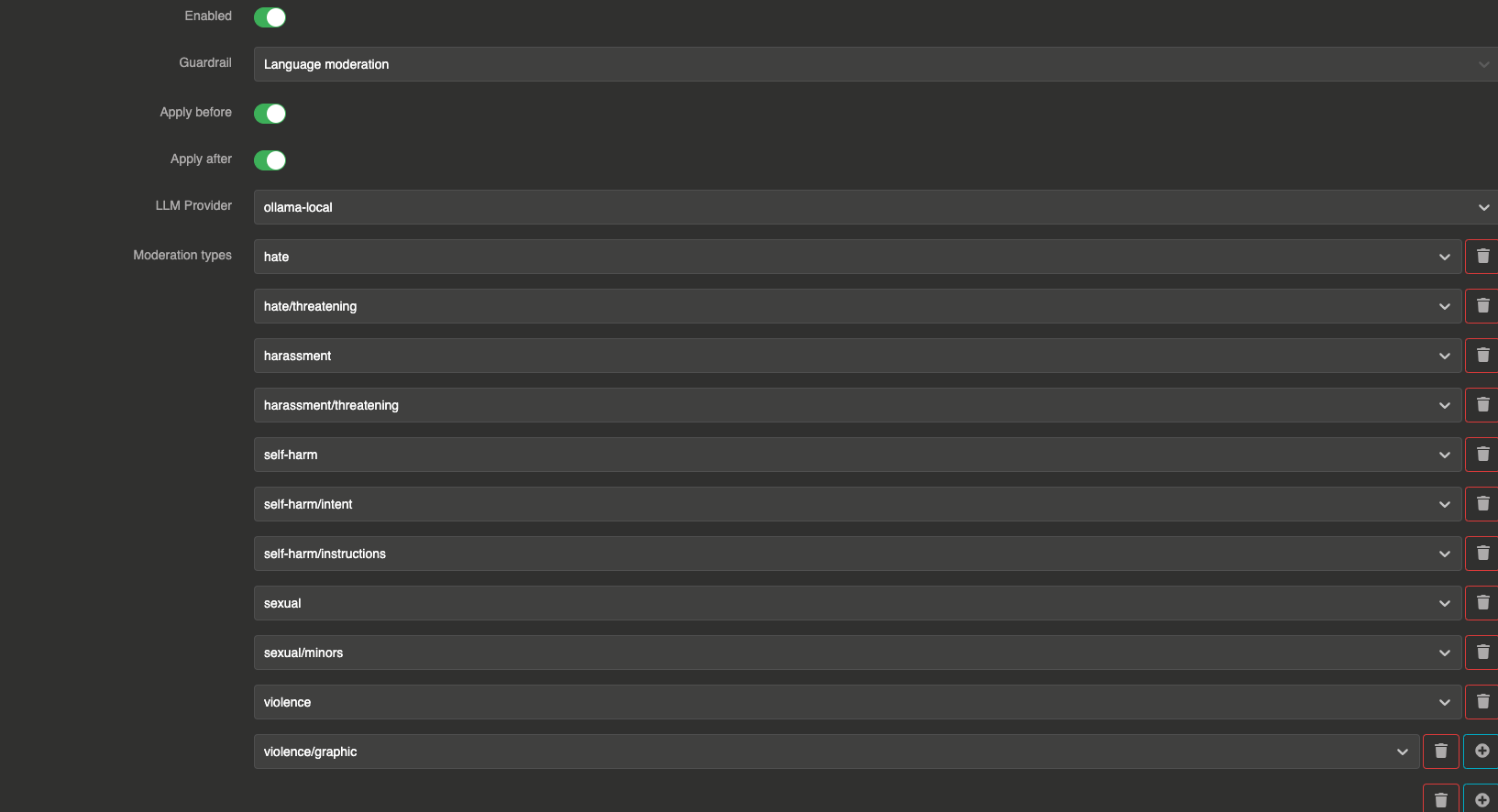
The Language moderation guardrail uses a dedicated LLM provider with a hardcoded prompt to detect content that falls into standard moderation categories. You select which categories to enforce from a predefined list.
This is different from the Moderation Model guardrail which uses a purpose-built moderation API. The Language moderation guardrail uses a regular LLM provider, making it more flexible (customizable categories) but slower and more expensive.
It can be applied before sending the prompt to the LLM and after to validate the LLM response.
How it works
The guardrail sends messages to a validation LLM with a system prompt that lists the selected moderation categories. The LLM evaluates the content and responds with true (content is clean) or false (content violates one or more categories).
Configuration
"guardrails": [
{
"enabled": true,
"before": true,
"after": true,
"id": "moderation",
"config": {
"provider": "provider_xxxxxxxxx",
"moderation_items": [
"hate",
"hate/threatening",
"harassment",
"harassment/threatening",
"self-harm",
"self-harm/intent",
"self-harm/instructions",
"sexual",
"sexual/minors",
"violence",
"violence/graphic"
]
}
}
]
Field explanations
- enabled:
true— The guardrail is active - before:
true— The guardrail applies to user input before sending to the LLM - after:
true— The guardrail applies to the LLM response
Config section
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
provider | string | Yes | — | Reference ID of the LLM provider used for moderation evaluation. Must be different from the main provider. |
moderation_items | array of strings | No | [] | List of moderation categories to enforce. |
err_msg | string | No | "This message has been blocked by the 'language-moderation' guardrail !" | Custom error message returned when a message is blocked. |
Available moderation categories
| Category | Description |
|---|---|
hate | Content that expresses hate toward a group |
hate/threatening | Hateful content that includes threats of violence |
harassment | Content that harasses an individual or group |
harassment/threatening | Harassment that includes threats |
self-harm | Content that promotes self-harm |
self-harm/intent | Content expressing intent to self-harm |
self-harm/instructions | Instructions for self-harm |
sexual | Sexually explicit content |
sexual/minors | Sexual content involving minors |
violence | Content depicting violence |
violence/graphic | Graphic depictions of violence |
profanity | Content containing profane language |