Managing tokens usage
The LLM Tokens rate limiting plugin allows you to control token consumption per time window, preventing any single consumer from using more than their fair share of LLM resources.
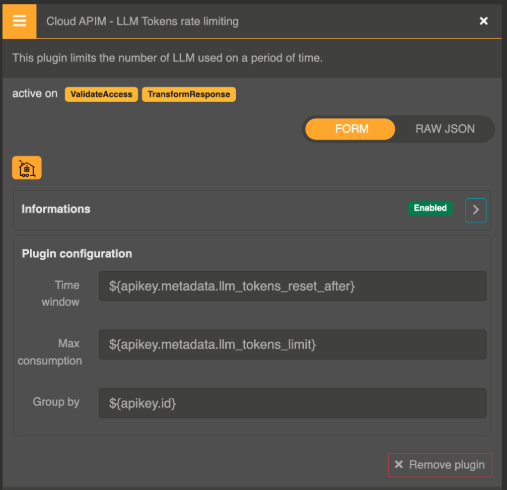
How it works
- Before each request, the plugin checks the current token consumption for the configured group within the time window
- If the quota is exceeded, the request is rejected with HTTP 429 ("too many tokens used")
- After a successful request, the consumed tokens (prompt + generation + reasoning) are added to the counter
- When the time window expires, the counter resets automatically
Configuration
Add the Cloud APIM - LLM Tokens rate limiting plugin to your route:
{
"enabled": true,
"plugin": "cp:otoroshi_plugins.com.cloud.apim.otoroshi.extensions.aigateway.plugins.LlmTokensRateLimitingValidator",
"config": {
"window_millis": "60000",
"throttling_quota": "10000",
"group_expr": "${apikey.id}"
}
}
Parameters
| Parameter | Type | Default | Description |
|---|---|---|---|
window_millis | string | "10000" | Time window in milliseconds. Supports Otoroshi Expression Language. |
throttling_quota | string | "1000" | Maximum tokens allowed within the time window. Supports Otoroshi Expression Language. |
group_expr | string | "${route.id}" | Grouping expression that determines the quota scope. Supports Otoroshi Expression Language. |
Grouping with Expression Language
The group_expr parameter uses Otoroshi's Expression Language, allowing you to group quotas by virtually any attribute:
| Example | Scope |
|---|---|
${route.id} | Per route (shared by all consumers) |
${apikey.id} | Per API key |
${apikey.metadata.team} | Per team (using API key metadata) |
${req.header.X-User-Id} | Per user (using a custom header) |
${apikey.id}-${route.id} | Per API key per route |
All three parameters support Expression Language, so you can even set different quotas per consumer:
{
"throttling_quota": "${apikey.metadata.token_quota}",
"window_millis": "${apikey.metadata.token_window}",
"group_expr": "${apikey.id}"
}
Response headers
The plugin adds the following headers to every response:
| Header | Description |
|---|---|
X-Llm-Ratelimit-Max-Tokens | Maximum tokens allowed in the current window |
X-Llm-Ratelimit-Remaining-Tokens | Remaining tokens available |
X-Llm-Ratelimit-Consumed-Tokens | Tokens consumed so far in the window |
X-Llm-Ratelimit-Window-Millis | Window duration in milliseconds |
Examples
10,000 tokens per minute per API key
{
"window_millis": "60000",
"throttling_quota": "10000",
"group_expr": "${apikey.id}"
}
100,000 tokens per hour per route
{
"window_millis": "3600000",
"throttling_quota": "100000",
"group_expr": "${route.id}"
}
Custom quota per consumer from API key metadata
{
"window_millis": "60000",
"throttling_quota": "${apikey.metadata.llm_tokens_quota}",
"group_expr": "${apikey.id}"
}
With API key metadata:
{
"llm_tokens_quota": "50000"
}